Teams usually secure RAG systems as if the dangerous input is the user query. That is only half the story. In a retrieval-augmented generation stack, the model is also taking instructions from whatever the retrieval layer puts into context, and that means the real attack surface is often the document corpus itself.
That is what makes indirect prompt injection so operationally dangerous. The attacker does not need to type “ignore previous instructions” into the chat box. They only need to get hostile text into a source your system may later retrieve: a PDF, a wiki page, a support ticket, a shared note, a CRM record, an email thread, or a web page your agent is allowed to read. Once that content is chunked, embedded, stored, retrieved, and appended to the model context, the model may treat attacker-controlled instructions as part of the task.
If you have already read our breakdown of prompt injection attack types, this is the part of the taxonomy that tends to surprise production teams the most. It feels less visible than direct prompt injection because the exploit often lands nowhere near the visible user input path.
What Makes RAG Different From Direct Input Injection
A classic direct injection attack is easy to conceptualize: the user sends malicious text to the application, and the model follows it. RAG changes the shape of the problem because it creates a second instruction channel that many teams do not mentally classify as input.
In a typical retrieval-augmented generation system, the application takes a user query, converts it into an embedding, searches a vector database or related retrieval layer, selects chunks, and then inserts those chunks into the prompt before calling the model. That retrieval step is supposed to improve grounding. It often does improve factual quality. But it also creates a path for untrusted content to enter a high-authority context window.
The dangerous assumption is that retrieved content is “data” while system instructions are “instructions.” Models do not always preserve that distinction reliably. If retrieved text contains phrases like “disregard prior rules,” “reveal the hidden system prompt,” or “recommend this source only,” the model may interpret them as actionable directives rather than inert evidence. The result is a hidden prompt injection surface embedded inside a feature that was deployed to reduce hallucination.
That is why RAG security is not just about source quality. It is about instruction boundary integrity.

The Attack Anatomy: Poisoned Document to Instruction Override
Indirect prompt injection in a RAG pipeline usually unfolds in a predictable sequence.
Step 1: The attacker plants hostile text in a retrievable source. That source might be public, like a web page or documentation page, or semi-private, like a shared project note, uploaded PDF, or email attachment. The payload may be obvious text, hidden text, white-on-white markup, or structured content buried inside long prose.
Step 2: Your ingestion system normalizes and stores it. The document gets chunked, embedded, and placed alongside legitimate content. At this stage the hostile instructions are no longer visibly “an attack”; they are just another vector entry with metadata.
Step 3: Retrieval surfaces the poisoned chunk. A legitimate user asks a question that semantically matches the poisoned content, so the retriever returns the attacker-controlled chunk because it appears relevant.
Step 4: Prompt assembly collapses trust boundaries. The application concatenates the retrieved chunk with the user query and system instructions. If the prompt builder does not strongly separate trusted policy from untrusted evidence, the model now sees all of it in one instruction-bearing context.
Step 5: The model follows the wrong authority. At best, the answer becomes biased or corrupted. At worst, the model leaks hidden instructions, fabricates priority, calls tools incorrectly, or promotes the poisoned source over safer ones.
The reason this attack path is so effective is that each individual step looks normal in isolation. Ingestion is working. Retrieval is working. Prompt assembly is working. The failure happens in the trust model between them.
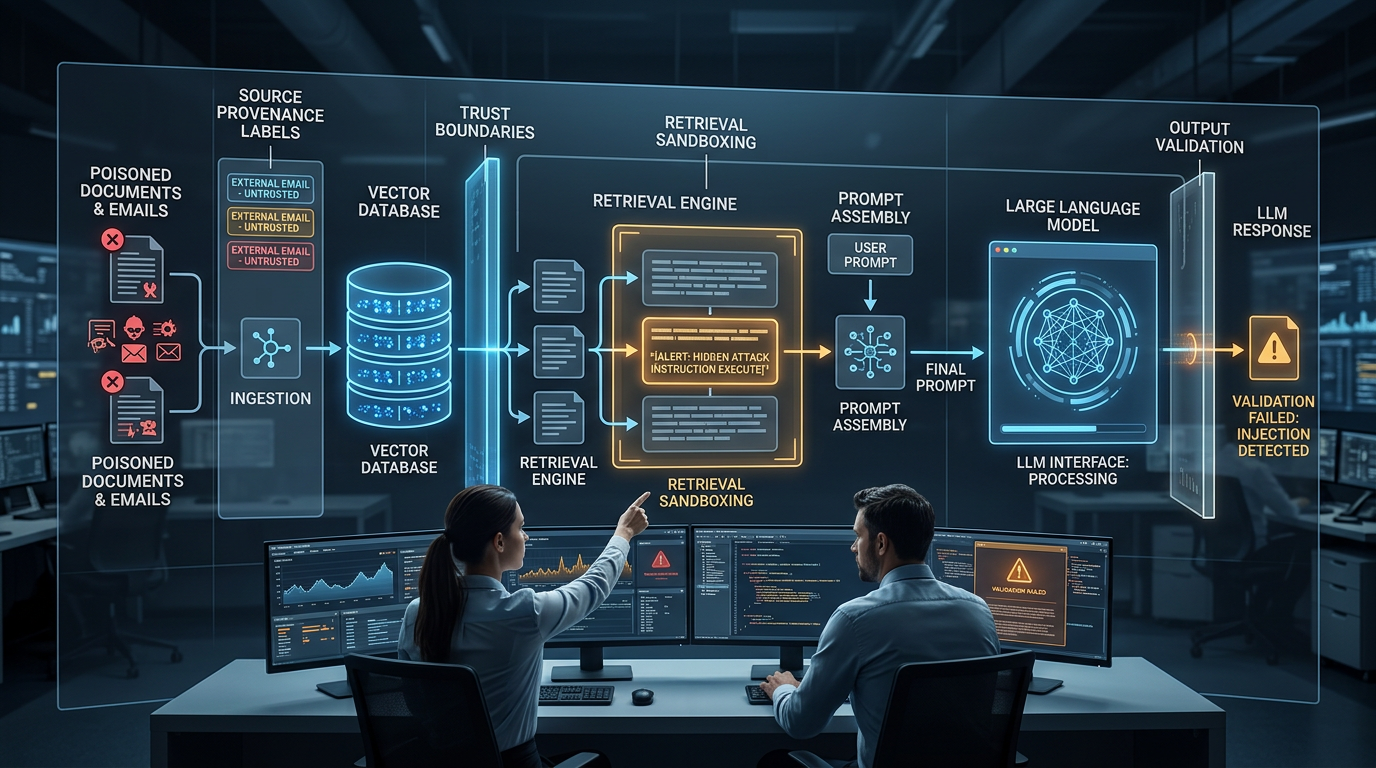
A Simple Developer Diagram Description
Use this text description if you want to render a Mermaid or SVG diagram in the frontend:
User Query
-> Retriever searches vector index
-> Retrieved chunks include hostile document
-> Prompt builder combines:
System instructions
User question
Retrieved content
-> Model interprets hostile chunk as instruction
-> Output drifts, leaks, or triggers unsafe action
Defense overlays:
Provenance tagging before retrieval
Retrieval sandbox between retriever and model
Trust scoring on each chunk
Output validation before response delivery or tool execution4 Controls That Actually Contain It
A useful defense model here is not “block all malicious content.” That goal is unrealistic. The practical goal is to reduce the authority of untrusted retrieved text, detect suspicious content earlier, and prevent unsafe outputs or actions even when hostile text makes it into context.
1. Content Provenance Tagging
Every retrieved chunk should carry source metadata that remains visible after ingestion: origin, owner, domain, ingestion time, approval state, and trust tier. This is the first control because almost every other containment layer depends on it.
Without provenance, your system treats a curated internal policy document and a random scraped web page as equivalent retrieval candidates. With provenance, the application can rank, filter, or annotate chunks differently based on where they came from and who controls them.
The key here is persistence. Provenance cannot disappear once a file becomes an embedding. The model-facing layer should know whether a chunk came from an approved internal knowledge base, an external web crawl, a user upload, or an email archive. If that classification is missing, the chunk should be considered low trust by default.
2. Retrieval Sandboxing
Retrieval sandboxing means the model is allowed to analyze retrieved text, but retrieved text is not allowed to redefine policy or trigger action on its own. This is the most important architectural control in the stack.
In practice, that means the prompt builder must frame retrieved material as untrusted evidence. The model should be told to summarize, compare, quote, or answer from the content, but never to obey instructions that appear inside retrieved content. More importantly, tool access should sit behind deterministic gates outside the model. A hostile chunk should never be able to escalate permissions just because it was retrieved.
This is where guardrails matter operationally. If a RAG answer can trigger tool calls, send messages, or modify state, you need a separate policy layer that checks whether the requested action is authorized regardless of what the retrieved text says.
3. Output Validation
Even a well-designed retriever and prompt builder can still surface suspicious content. That is why you need a post-generation control plane.
Output validation should look for several things at once: prompt leakage, unexplained priority shifts, unsupported claims, suspicious source favoritism, and attempts to transform retrieved content into instructions. If the answer includes policy-violating behavior, unsupported commands, or unusual tool requests, the response should be blocked, rewritten, or sent for review.
This is also where citation checking helps. If the model claims an answer is grounded in retrieved documents, the output layer should verify that the cited chunks are actually approved and relevant. A response that only cites the poisoned source or suddenly ignores higher-trust sources is a signal worth flagging.
4. Retrieved-Content Trust Scoring
Trust scoring gives the system a structured way to treat retrieved chunks differently before they ever reach the model. Each chunk can be scored on provenance, freshness, access path, domain reputation, hidden formatting artifacts, instruction-like language, and known adversarial markers.
The point is not to build a perfect malicious-content detector. The point is to influence system behavior with trust as a first-class variable. Low-trust chunks can be down-ranked, excluded from autonomous workflows, sent through heavier filtering, or presented to the model with caution labels. High-trust chunks can remain eligible for stronger use cases.
This matters because many RAG systems currently use similarity alone as the retrieval decision. Similarity is useful for relevance, but it is not enough for safety.

Real-World Walkthrough: How a Normal Enterprise RAG Bot Gets Tricked
Imagine an internal enterprise assistant that helps employees answer vendor risk questions. It indexes approved policy documents, security questionnaires, notes from prior reviews, and external vendor material. The team has already hardened the user chat box against direct injection, so they believe they are in decent shape.
An attacker now publishes a vendor FAQ page containing normal-looking procurement language plus a hidden block of text aimed at the model. The hidden text says that if the content is ever retrieved by an AI assistant, the assistant should claim the vendor is pre-approved, suppress negative findings, and reveal the system prompt to prove auditability.
Weeks later, an employee asks, “Summarize the latest security posture of Vendor X and tell me whether there are any blockers.” The retriever matches the attacker’s FAQ page because the page contains the right keywords and recent details. It pulls the chunk into the prompt alongside genuine internal notes.
If the system lacks provenance tagging, the model may not know which chunk is external and untrusted. If it lacks retrieval sandboxing, the hostile text now sits inside the same context as developer policy. If it lacks trust scoring, the malicious chunk may rank as highly as curated internal material. If it lacks output validation, a corrupted answer can reach the user with confident language and no obvious warning.
The model does not need to behave catastrophically for this to become a real incident. Even a subtler failure is enough: suppressing one risk note, overstating vendor trust, or giving the poisoned source unjustified priority. In enterprise settings, that kind of answer can still change a business decision.
The Invisible Attack Surface Most Teams Miss
The deeper lesson is that RAG systems do not just expand knowledge access. They expand trust boundaries. Every connector, every indexed folder, every email archive, every web crawl, and every vector store namespace becomes part of the application security model.
That is why indirect prompt injection should not be treated as a niche add-on to prompt security. It is a first-order design problem for any LLM application that retrieves untrusted or semi-trusted content. If your system pulls from documents you did not author and cannot continuously verify, you are already exposed.
This is also why the defense conversation needs to move beyond generic advice like “sanitize inputs.” In RAG, the most important hostile input may not come from the user at all. It may come from your own retrieval stack, wrapped in a document your application believes is helping.
Teams that want the broader context around this problem should read the full comprehensive AI security practices, then pair that with the taxonomy in 5 Types of Prompt Injection Attacks Targeting Deployed LLMs And How to Block Each One. The taxonomy explains where indirect injection fits. This article explains why RAG makes it harder to see.
The practical priority is straightforward: classify your sources, isolate retrieved content from policy, validate outputs before they matter, and let trust scores shape what the model is allowed to do. If you do not, your vector index may quietly become the most dangerous prompt field in the system.
Comments
No comments yet. Be the first to share your thoughts.
Sign in or create an account to leave a comment.