
What is RAG? (RAG Meaning in AI)
Retrieval-Augmented Generation (RAG) is a framework that combines the creative power of a Large Language Model like ChatGPT with the accuracy of a search engine. If you are trying to understand what RAG means in AI, the short version is this: it lets a model look up trusted information before generating an answer, instead of relying only on what it learned during its original training.
Put simply, this is retrieval augmented generation explained: the system acts like an open-book test. When asked a question, it first searches a private or public database for relevant documents, then “reads” those documents, and finally uses the model to summarize the findings into a natural-sounding answer. That is the rag in ai meaning most teams care about, and it also answers what is a RAG system: a model-plus-retrieval pipeline that grounds answers in external evidence. This process ensures the AI’s output is “grounded” in verifiable facts, drastically reducing the risk of errors while allowing the model to answer questions about events or data that happened after its training was completed.
Why It Matters
RAG is the “bridge” that makes AI usable for enterprises and professionals who demand 100% factual accuracy. While the conversational ability of LLMs is impressive, their tendency to Hallucinate makes them dangerous for tasks like checking medical records, analyzing financial markets, or reciting company policy. RAG solves this by shifting the model’s role from a “creator of facts” to a “synthesizer of evidence.”
The technology is particularly critical because of the “knowledge cutoff” problem. Most frontier AI models are trained on data from months or even years ago. Without RAG, an AI wouldn’t know about a news event that happened this morning or a product update your company released yesterday. By allowing the AI to “look things up” in a Vector Database, RAG transforms static models into live, dynamic systems that can interact with the real world’s ever-changing information. This makes RAG the standard architecture for AI-powered search engines, legal research tools, and corporate knowledge management platforms.
How Does RAG Work?
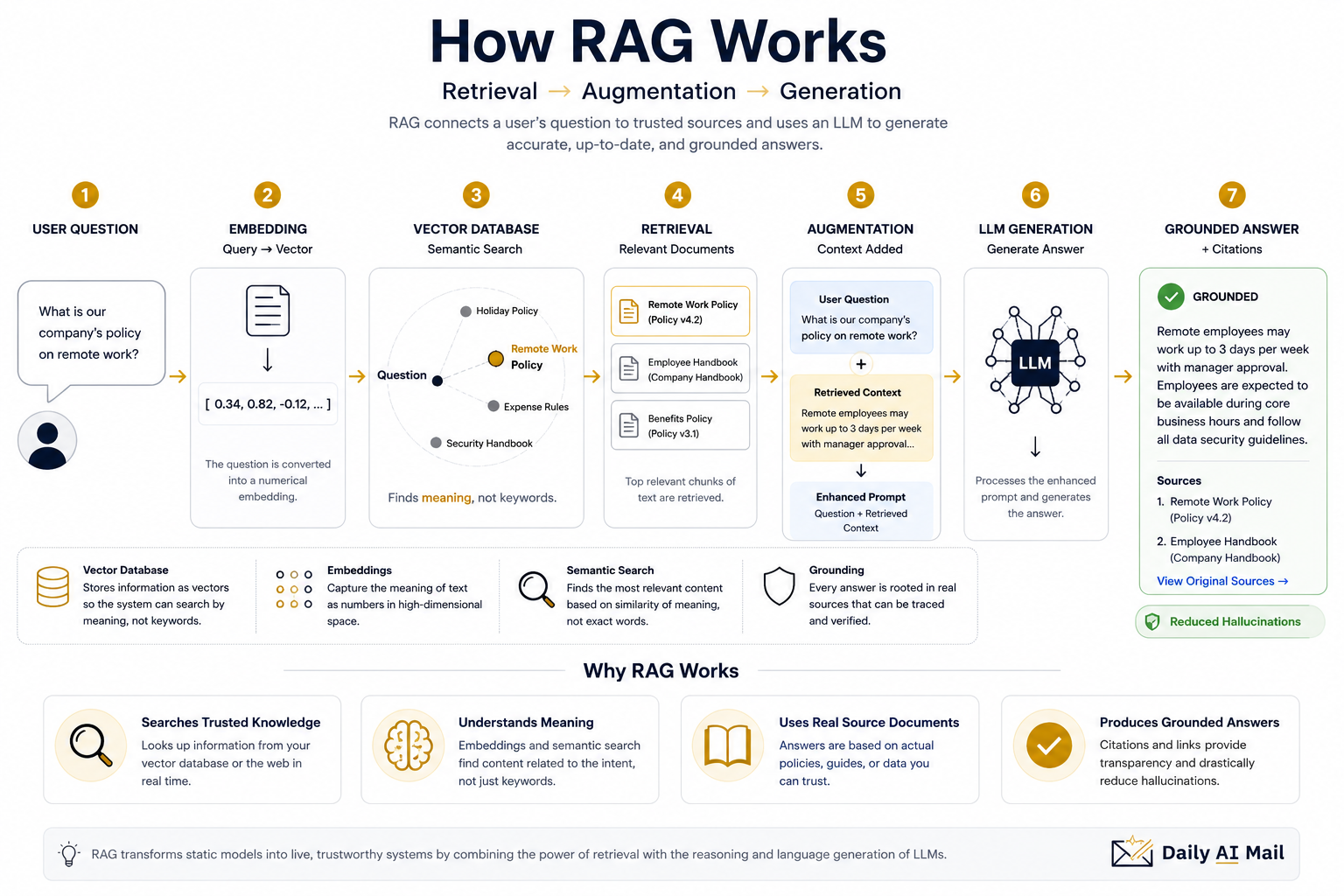
A RAG system works through a sophisticated multi-step pipeline.
- The Retrieval Stage: When a user submits a query (e.g., “What is our company’s policy on remote work?”), the system doesn’t send the prompt directly to the LLM. Instead, it converts the query into a numerical vector called an Embedding. It then uses this vector to search a database for “semantically similar” documents—meaning it finds information related to the meaning of the question, not just the exact keywords.
- The Augmentation Stage: The system takes the most relevant chunks of text it found (the “retrieved” data) and inserts them directly into the user’s original prompt. The new prompt looks something like: “Here is some context from our company handbook: [Retrieved Content]. Based ONLY on this context, answer the user’s question: ‘What is our policy on remote work?’”
- The Generation Stage: The Large Language Model then processes this “augmented” prompt. Because the answer is right there in the text, the model doesn’t have to “guess” or “remember.” It simply uses its language-processing skills to summarize the facts clearly and concisely.
This entire process happens in milliseconds. Crucially, because the system “knows” exactly which documents it used to find the answer, it can provide citations and links back to the source material, allowing a human user to verify the response with one click. This is known as Grounding.
Examples Of RAG In AI
RAG shows up anywhere the model needs trusted, current, or organization-specific knowledge. The examples below are the clearest places to see it in the wild, because each one blends retrieval with generation in a way that is easy to explain, easy to test, and easy to link back to real business value.
AI Search And Answer Engines
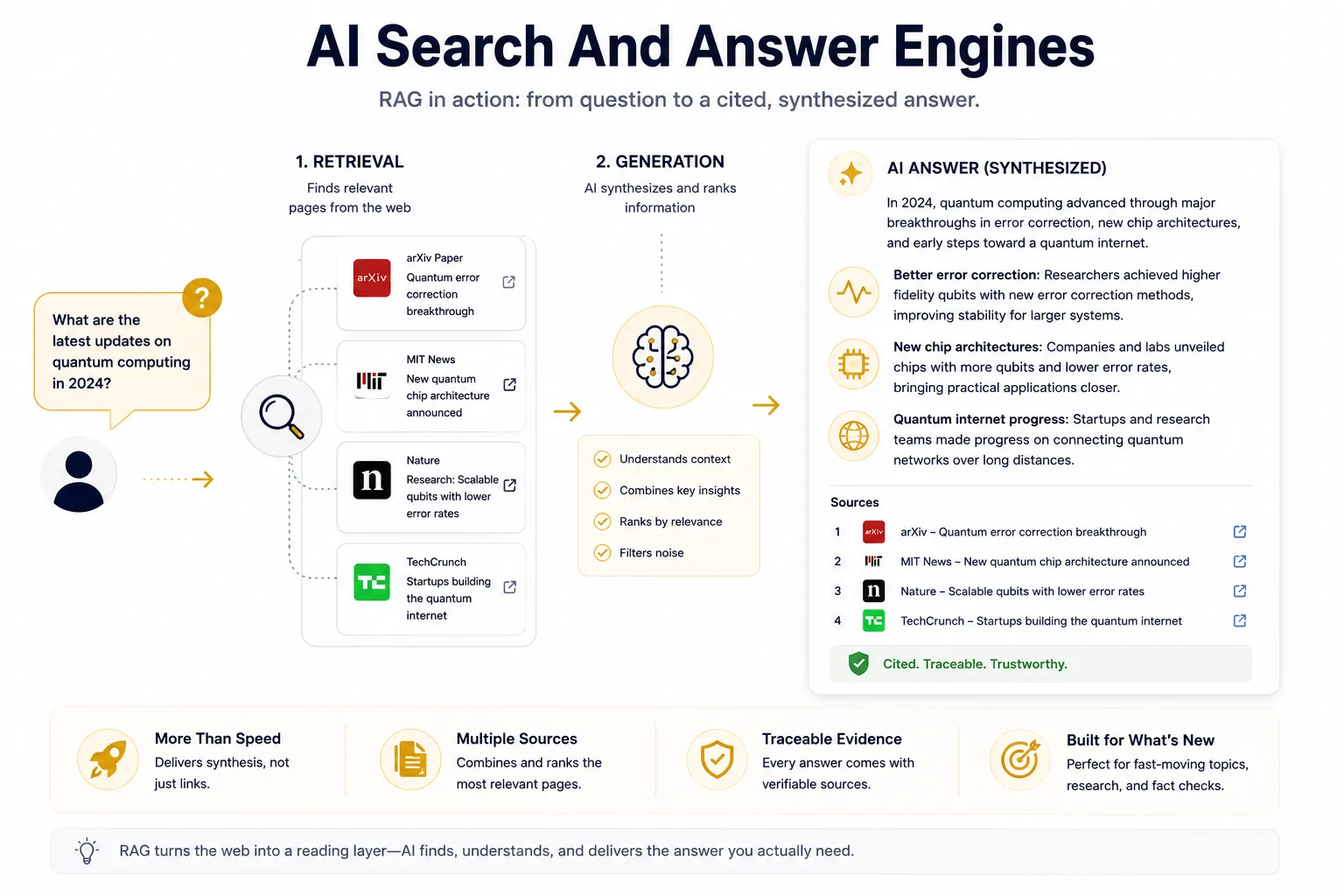
AI search is the most visible example of RAG in AI because it is built around the promise of answering a question without forcing the user to open ten tabs. Systems like Perplexity, You.com, and Google Gemini-style web answers rely on retrieval to collect relevant pages, then use generation to compress them into one cited response. The value is not just speed; it is synthesis. A good RAG search system can combine multiple sources, rank them by relevance, and surface a concise answer with traceable evidence. That makes it more than a search box and more than a chatbot. It becomes a reading layer over the web, one that is especially useful for rapidly changing topics, technical research, and fact checks where the source matters as much as the answer.
Internal Knowledge Assistants
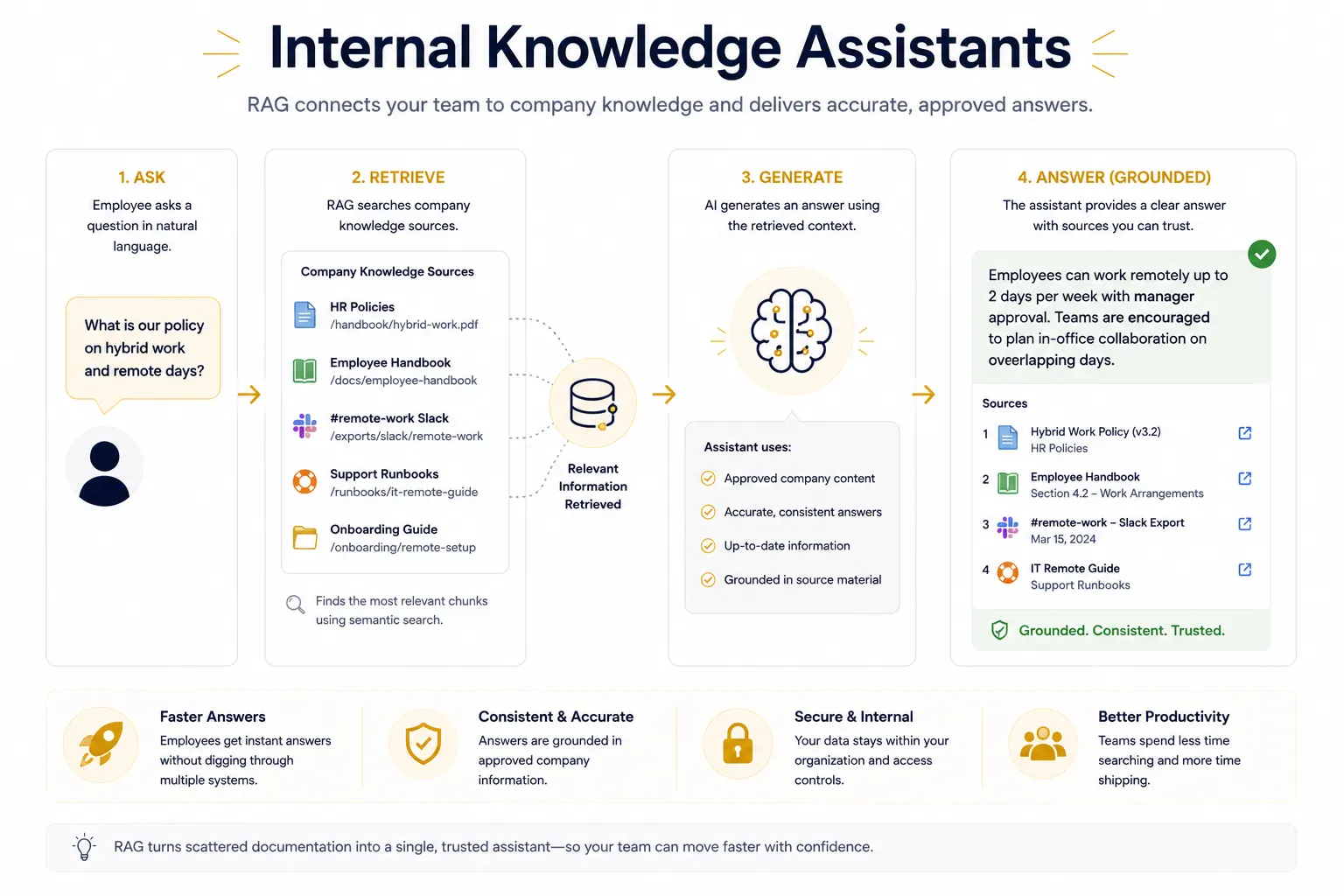
One of the strongest enterprise use cases for RAG is the internal knowledge assistant. Companies keep policies, onboarding material, product docs, support runbooks, and Slack exports spread across systems that are difficult to search with keywords alone. RAG solves that by letting an employee ask a plain-language question and then retrieving the most relevant internal documents before drafting the answer. That is useful for onboarding, operations, HR, sales enablement, and executive support. It also reduces the risk of inconsistent answers because the assistant can ground responses in approved source material rather than improvising. In practice, this is where RAG turns from a clever demo into infrastructure: it helps teams move faster while keeping answers tied to the company’s actual documentation.
Customer Support Chatbots
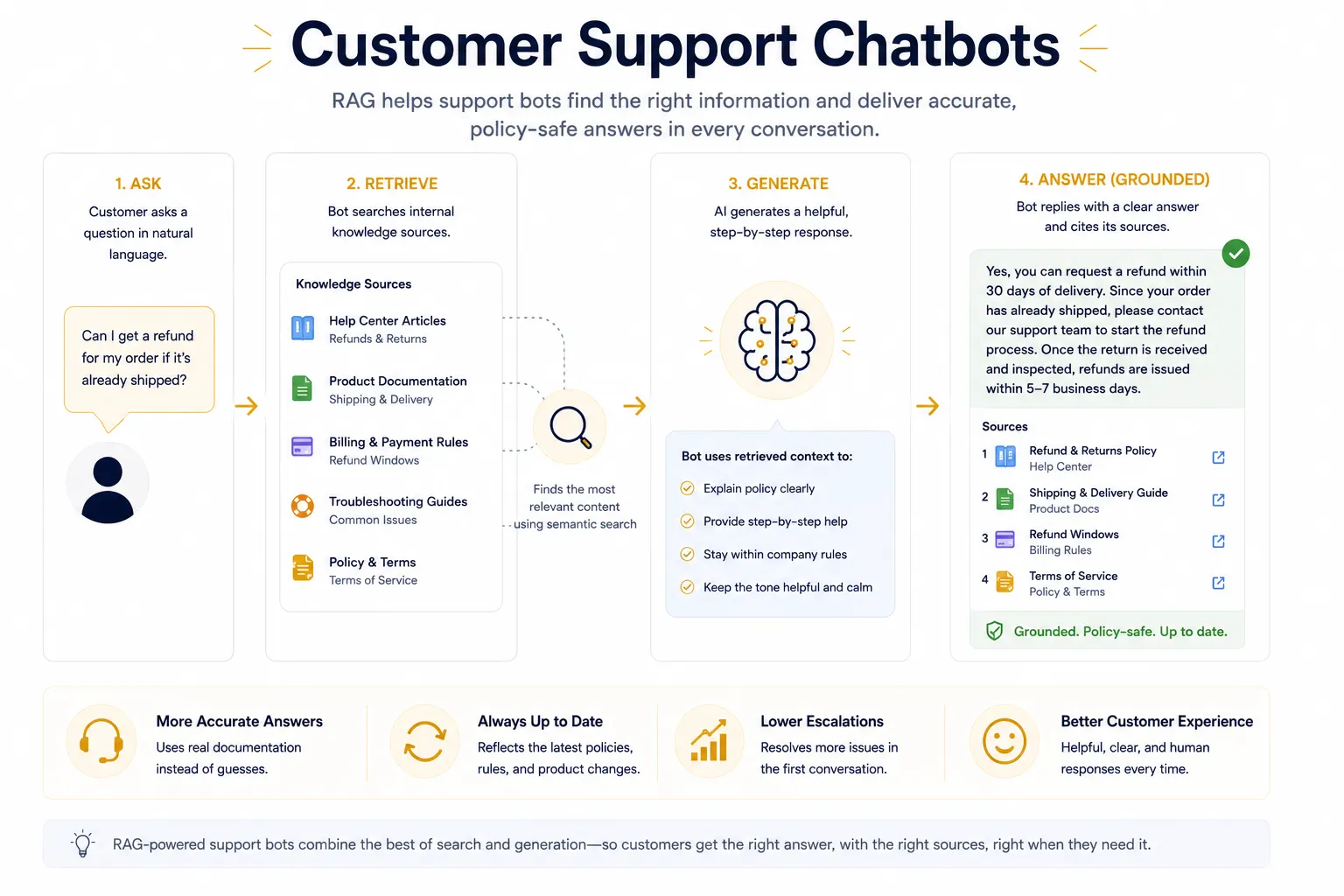
Customer support is another classic RAG example because support quality depends on policy fidelity, not just conversational fluency. A RAG-powered support bot can search help-center articles, product documentation, billing rules, and troubleshooting guides before answering a customer’s question. That means it can handle more than canned intents and short keyword matches; it can explain workflows, compare product states, and give step-by-step help while staying inside policy. It is especially valuable when a company updates its terms, shipping rules, refund windows, or software behavior and needs the bot to reflect those changes quickly. The retrieval layer keeps the assistant current, while the generation layer makes the response readable and calm. Done well, this lowers escalation volume and gives customers answers that feel less scripted.
Legal And Compliance Research

Legal and compliance teams use RAG when they need answers that are grounded in source documents but still readable enough to act on. A lawyer, paralegal, or compliance analyst might ask a system to summarize policy language, compare clauses across contracts, or find the most relevant guidance inside a regulatory library. RAG is a good fit because the answer must be tied to source text, citations, and context, not a generic model memory. It can help teams review precedent, locate definitions, and trace policy lineage across long document sets. The key advantage is speed without losing accountability: the model can draft a usable summary, but the retrieval step keeps the human reviewer anchored to the actual clause, filing, or regulation that matters.
Developer Documentation And Coding Help
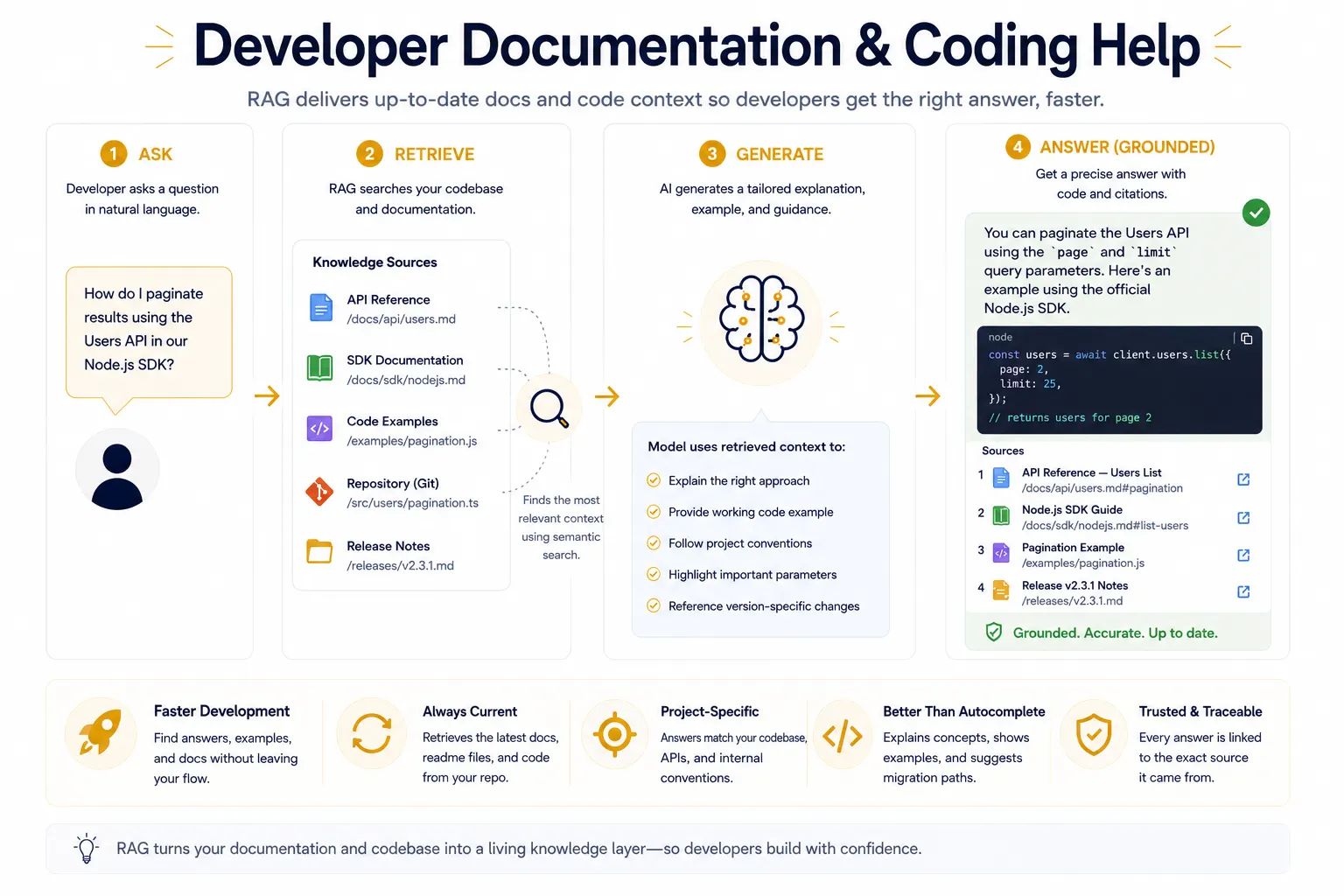
RAG also shows up in developer tools that answer questions about APIs, SDKs, repositories, and internal engineering docs. Instead of relying only on training data, the assistant can retrieve the latest readme files, code comments, release notes, and schema definitions, then generate an answer specific to the project in front of it. That is a big deal for teams working with fast-changing codebases, because the model can stay aligned with current interfaces and local conventions. It is also a better fit than plain autocomplete when the user needs an explanation, an example, or a migration path. In this setting, RAG acts like a living documentation layer: it helps developers move faster, but it keeps the response tethered to the code and docs that actually exist.
Healthcare And Clinical Reference

Healthcare teams use RAG when the cost of a vague or outdated answer is too high. A clinical support system can retrieve approved medical guidelines, policy documents, care pathways, or internal reference material before drafting a response for a clinician or administrator. This does not replace medical judgment, but it can make large volumes of information easier to navigate and cross-reference. RAG is especially useful when the question is procedural, like which policy applies, where a guideline lives, or what the current approved protocol says. The retrieval layer gives the model the right source context; the generation layer turns that context into something human beings can read quickly. In regulated settings, that combination is what makes the system practical rather than risky.
Limitations
RAG is highly effective, but it is not infallible. Its accuracy depends entirely on the “Retrieval” stage. If the search engine part of the system fails to find the correct document—or worse, finds a document that is outdated or incorrect—the LLM will faithfully summarize that bad information. This is known as the “Garbage In, Garbage Out” problem.
There is also the challenge of the Context Window. LLMs have a limit on how much text they can “read” at one time. If the retrieved documents are too long or there are too many of them, the system must decide which parts to cut, which can sometimes lead the AI to miss the most important detail.
Finally, building a high-performance RAG system is technically complex. It requires maintaining a Vector Database, constantly updating embeddings, and “tuning” the search algorithm to ensure the AI isn’t getting distracted by irrelevant documents that just happen to share a few keywords with the user’s query. Despite these hurdles, RAG is currently the most robust method for making AI reliable enough for professional work.
FAQ
What does RAG mean in AI?
RAG means Retrieval-Augmented Generation, a method that lets an AI model retrieve relevant external information before generating an answer. This helps the model produce responses that are more accurate, current, and grounded in source material.
How does retrieval augmented generation work?
Retrieval augmented generation works by converting a user’s query into an embedding, finding semantically relevant documents, adding those documents to the prompt, and then asking the language model to generate an answer from that context. The result is a response based on retrieved evidence rather than the model’s memory alone.
What is a RAG system?
A RAG system is an AI architecture that connects a language model to external data sources such as documents, websites, or internal knowledge bases. It typically includes retrieval, augmentation, and generation steps so the model can answer with information it has looked up.
Related Terms
- Vector Database: The specialized infrastructure that stores information in a way that RAG systems can search by meaning rather than just keywords.
- Embeddings: The mathematical representations of text that allow RAG systems to calculate which documents are relevant to a user’s query.
- Large Language Model (LLM): The conversational engine that takes the retrieved information and turns it into a natural-sounding response.
- Hallucination: The primary AI error that RAG is designed to prevent by anchoring the model to external facts.
- Grounding: The process of ensuring that every part of an AI’s answer can be traced back to a specific, verifiable source document in the RAG pipeline.
- Context Window: The “workspace” where the RAG system places the retrieved documents for the LLM to analyze.
Further Reading
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — The original 2020 research paper from Meta AI that introduced the RAG framework.
- What is RAG? (IBM Blog) — A practical, business-focused breakdown of how RAG is being used in modern industry.
- Vector Databases and RAG: A Developer’s Guide (Pinecone) — A technical guide on the infrastructure required to build a reliable RAG pipeline.
- Wikipedia: Retrieval-augmented generation — A broad overview of the history, development, and architectural variations of RAG systems.