I wanted a simple answer to a question every editor, writer, and AI publisher now asks quietly: which model is actually better for writing?
Not better at solving a benchmark. Not better at coding a demo. Better at doing the real newsroom work: turning a brief, a source, and a messy information set into an article a human editor can shape and publish.
So I gave Claude, Gemini, and GPT-4o the same task.
The assignment was to write an AI news article about Anthropic’s Project Glasswing update, using the same source material, the same editorial angle, and the same publishing standard. The story itself was useful for this test because it had real complexity. It involved security claims, vulnerability numbers, company positioning, open-source implications, and a bigger question about whether AI can now find software flaws faster than humans can verify and patch them.
That is exactly where AI writing either becomes useful or exposes itself quickly.
A weak model turns the source into a press release. A careless model overstates the facts. A generic model produces a technically correct summary that nobody wants to finish. A better writing model understands the tension behind the facts and builds the article around it.
All three models produced something readable. None failed completely. But they did not succeed in the same way.
GPT-4o gave me the safest and cleanest draft. Gemini gave me the best structure and the most useful packaging ideas. Claude gave me the strongest editorial voice and the clearest sense of why the story mattered.
One important note before publishing: GPT-4o is now a historical reference inside this comparison. OpenAI’s current ChatGPT help documentation says GPT-4o was retired from ChatGPT on February 13, 2026, so this article should be read as a writing comparison based on a test performed when GPT-4o was still part of the workflow. Pricing and plan names also change quickly in AI products. At the time of this draft, ChatGPT Plus is listed at $20 per month, Claude Pro is listed at $20 monthly or $17 per month on annual billing, and Google AI Pro is listed at $19.99 per month.
The test setup
Same brief, same sources, three different models, blind review
The test was designed to be simple enough to compare fairly and difficult enough to reveal meaningful differences.
I used the same brief for Claude, Gemini, and GPT-4o. I did not give one model a better instruction, a stronger example, or extra source context. Each model received the same topic, the same source material, and the same writing goal: produce a publishable AI news article from the provided information.
The source focused on Anthropic’s Project Glasswing update. Anthropic said Project Glasswing and Claude Mythos Preview had identified more than 10,000 high- or critical-severity vulnerabilities across important software. The story also included partner claims, open-source scanning numbers, disclosure concerns, and the broader security problem created when AI-assisted vulnerability discovery moves faster than patching capacity.
That gave the models several jobs at once.
They had to understand the factual timeline. They had to avoid treating every company claim as independent proof. They had to explain cybersecurity context without losing a general AI audience. They had to identify the real editorial angle. They had to write a headline, introduction, and section flow that could work for a technology publication.
I reviewed the outputs first without focusing on the model names. I wanted to judge the drafts as articles, not as products from brands I already had expectations about.
The review criteria were practical: headline strength, opening paragraph, structure, editorial voice, factual discipline, and how much human editing would still be needed before publication.
That last point matters. AI writing quality is not just about whether the text sounds fluent. It is about how much useful editorial work the model has already done.
A beautiful but risky draft can waste time. A clean but boring draft can still need a full rewrite. A structured draft can save the editor even if the voice is not final. The most useful AI writer is not always the one that produces the prettiest paragraph. It is the one that moves the article closest to publication without creating hidden risk.
What each model got right
GPT-4o played it safe and clean
GPT-4o produced the safest draft of the three, and readers comparing current access can check OpenAI’s ChatGPT pricing page because plan names and availability change often.
That is not a small thing. In news writing, safe and clean can be valuable. A draft that is easy to read, avoids unnecessary drama, and keeps most facts in the right order can save an editor time.
The GPT-4o article opened clearly. It understood that the Project Glasswing story was not only about Anthropic finding vulnerabilities. It also understood the second layer of the story: AI may now be accelerating bug discovery faster than the security ecosystem can validate, disclose, and patch those bugs.
That was the correct frame.
The strongest part of GPT-4o’s output was sentence control. The paragraphs were readable. The article did not feel overloaded with cybersecurity jargon. It did not turn every number into hype. It gave me a draft that looked like a standard technology news article and could be understood by a general AI audience.
For quick publishing workflows, that matters. If the goal is to produce a neutral first draft that does not embarrass the publication, GPT-4o did well.
But the same safety also limited the article.
The draft felt clean, but not memorable. It had structure, but not much shape. It had the facts, but not enough editorial force. It explained what happened, but it did not create a strong sense of why the reader should keep going.
The best use case for GPT-4o in this test was not final writing. It was cleanup. I would use it to tighten a paragraph, simplify a technical explanation, rewrite a clunky transition, or produce several headline variations after the editorial angle has already been chosen.
ChatGPT test prompt
Open in AI
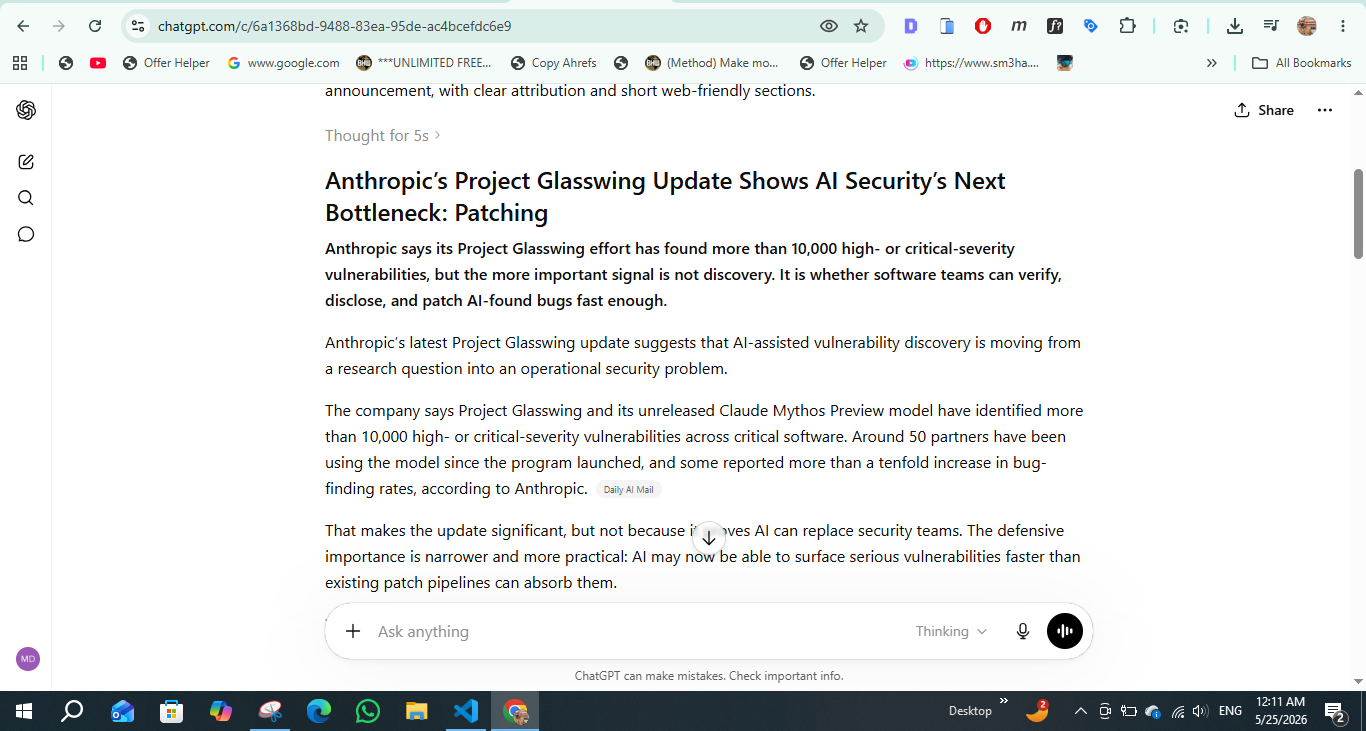
Source: Daily AI Mail testing prompt.
Gemini had the best structure and pull quotes
Gemini surprised me most in structure, especially as a model to weigh against Google’s current Google AI plans if you are comparing writing workflows across paid AI subscriptions.
Its draft had the strongest visual shape. The section rhythm was better. The article felt easier to break into a publishable page. It created more natural moments for screenshots, callouts, and pull quotes.
It identified the major contrasts inside the story: discovery versus patching, defensive AI versus misuse risk, company claims versus ecosystem pressure, and open-source maintainers versus automated vulnerability reports. Those contrasts helped the article feel less like a summary and more like an organized explanation.
It also produced several lines that could work as pull quotes or section callouts. The best of them captured the idea that the hard part is no longer only finding vulnerabilities, but deciding whether the security ecosystem can respond fast enough.
Gemini’s weakness was tone.
Some parts sounded too polished in a corporate way. It occasionally drifted toward language that felt like a conference panel summary rather than a newsroom article. It knew how to arrange the material, but it did not always keep the tension sharp enough.
That matters because a strong structure can still produce a weak article if the voice loses urgency.
For me, Gemini’s best role is the packaging editor. I would use it after the first draft exists to decide where the article drags, which sections need splitting, where a screenshot should go, what lines could become callouts, and how to make the page easier to scan.
Gemini test prompt
Open in AI
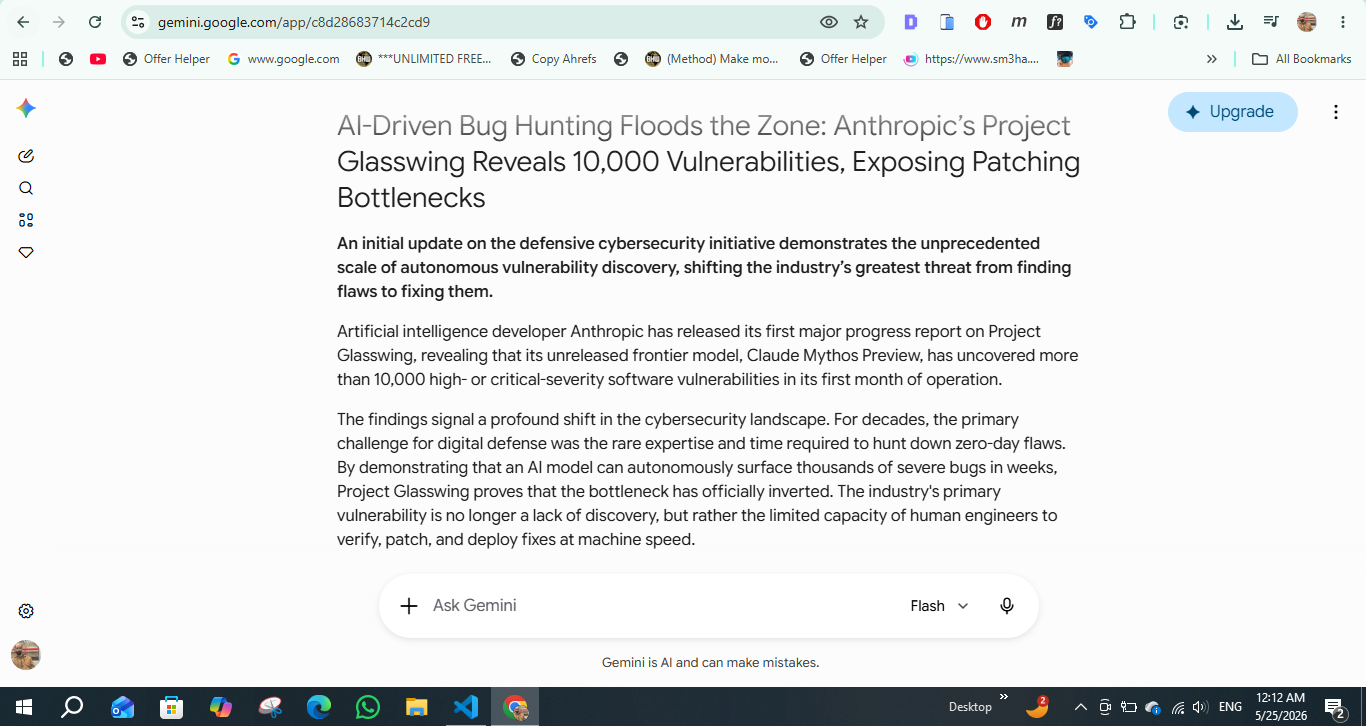
Source: Daily AI Mail testing prompt.
Claude had the strongest editorial voice
Claude produced the most convincing article, and readers evaluating it as a writing tool should compare that result against Anthropic’s current Claude pricing before choosing a plan.
It did not only summarize the source. It found the story.
Claude’s draft had stronger narrative movement. The paragraphs connected better. The article moved from fact to implication without feeling forced. It did not simply stack details. It explained why each detail mattered.
That is what I mean by editorial voice. It is not only style. It is judgment.
It also framed the risk more naturally. It did not treat AI-assisted security work as a simple win. It recognized the dual-use problem: the same kind of capability that helps defenders find bugs could also help attackers if similar systems become more broadly available.
Claude was not perfect. Some paragraphs needed trimming. A few sentences were more reflective than necessary for a direct news article. The structure was strong, but not as visually clean as Gemini’s.
But I would rather edit down a strong voice than inject life into a flat article. That is why Claude was the clear winner for this specific writing task.
Claude test prompt
Open in AI
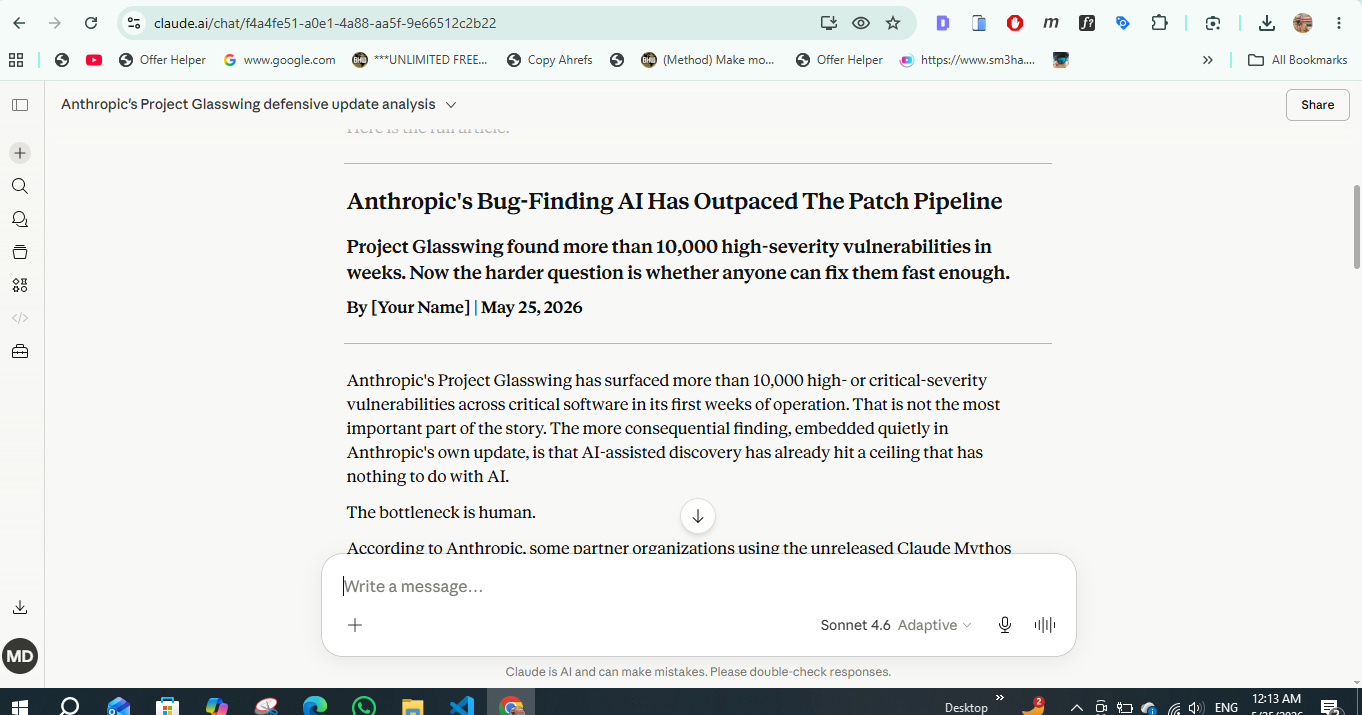
Source: Daily AI Mail testing prompt.
Where all three failed
None of them nailed the headline on the first attempt
The headline was the biggest shared failure.
That matters because headline quality is not a decorative issue. For Google Discover, the headline may be the whole entry point. The reader is not necessarily searching for this comparison. The headline has to create enough curiosity to earn attention without misleading the reader.
GPT-4o gave me safe headlines. They were accurate, but too predictable. They sounded like standard SEO titles rather than Discover-ready editorial headlines.
Gemini gave me better rhythm, but some headlines were too broad. They sounded polished, yet they lacked the specificity needed to make the article feel fresh.
Claude gave me the most interesting headline angles, but a few leaned too far into interpretation and needed tighter factual grounding.
That is a pattern I see often with AI headline writing. Models can generate many headline options, but they rarely understand the exact publishing environment unless you define it very clearly.
For this article, I would not use the first headline from any of the models. I would ask for 20 to 30 variations, group them by angle, remove anything too vague or too clickbait-driven, and then manually rewrite the best one.
The winning headline has to create a small information gap while staying honest. This one works because it tells the reader the experiment, the tools, and the tension. It does not hide the subject or promise a fake scandal.
Factual sourcing was a problem across the board
The second shared weakness was factual sourcing.
All three models sounded confident. That is exactly why the problem is serious.
A rough draft makes editors cautious. A fluent draft can make editors lazy. The smoother the AI writing sounds, the easier it becomes to assume the facts are stable.
That assumption is dangerous in AI news.
Product names change. Plan names change. Model availability changes. Subscription prices change. Companies update help documents. A sentence that was true last month can become outdated by the time the article is published.
The title uses GPT-4o because that was part of the original comparison idea and target keyword set. But OpenAI’s current help documentation says GPT-4o was retired from ChatGPT on February 13, 2026. That does not make the comparison unusable, but it means the article needs a clear time frame. It should not imply that readers can run the exact same test inside ChatGPT today using GPT-4o unless that is still available in their product experience.
Pricing needs the same caution. At the time of writing, ChatGPT Plus is listed at $20 per month, Claude Pro is listed at $20 monthly or $17 per month when billed annually, and Google AI Pro is listed at $19.99 per month. Those details should be checked again before publishing because AI subscription pages change often.
No model should be trusted to handle this from memory.
The safest editorial workflow is simple: let the model draft, but verify every changeable fact from a primary source. That includes subscription prices, plan names, model availability, release dates, launch timelines, company claims, benchmark results, product limitations, and anything connected to legal, medical, financial, or security implications.
For this specific test, the risk was not only the writing quality. The risk was that a model could write a beautiful article while quietly introducing outdated or unsupported details.
My verdict
The best AI writer depends entirely on what “better” means to you
Claude was the best writer in this test.
But that verdict needs context.
If “better” means clean, safe, and easy to polish, GPT-4o performed well. It gave me a stable draft with fewer strange moves. I would use it when I want a neutral starting point, a simpler rewrite, or a fast cleanup pass.
If “better” means structure, layout, and article packaging, Gemini was the strongest. It helped me see the article as a page. It created better section rhythm, stronger break points, and more useful pull-quote opportunities.
If “better” means editorial voice, narrative judgment, and the ability to identify the real story behind the source, Claude won.
Claude was the model I would trust most for a first serious editorial draft. Gemini was the model I would trust most for improving the article’s shape. GPT-4o was the model I would trust most for controlled cleanup.
That is why the better answer is not only “Claude wins.” The better answer is that each model belongs in a different part of the workflow.
What I now use for each stage of my editorial workflow
After this test, I would not ask one model to write, edit, fact-check, optimize, and package the entire article alone.
Instead, I would split the workflow into stages.
First, I would use an AI model to extract the facts from the source. This is not the creative stage. I want the model to list the claims, numbers, named entities, dates, links, and risky statements that require verification.
Second, I would use Claude for the first editorial draft. This is where the article needs a strong angle. I do not want a flat summary that I have to rescue later. I want a draft that already understands the tension behind the story.
Third, I would use Gemini to improve structure and packaging. I would ask it where screenshots should go, which section needs a stronger break, which line could become a pull quote, and whether the flow works for a reader scrolling on mobile.
Fourth, I would use ChatGPT for cleanup and variation. I would ask it to tighten paragraphs, simplify technical explanations, improve transitions, reduce repetition, and generate headline alternatives for different platforms.
Fifth, I would fact-check manually. No model replaces this step. If the article includes prices, release dates, model availability, product claims, or company statistics, those details need to be checked against primary sources before publication.
That workflow gives each model a job it can perform well. It also keeps the editor in control.
Claude gave me the best writing foundation. Gemini gave me the best structure. GPT-4o gave me the safest cleanup pass. Used alone, each model had weaknesses. Used together, they created a stronger workflow than any single model could provide.
That is how I now think about AI writing tools. They are not replacement writers. They are specialized editorial assistants. One can help you find the story. One can help you package it. One can help you polish it.
But the responsibility for the final article still belongs to the publisher.
The model can write the draft. It cannot own the judgment.
That is why Claude won this test, but the editor still wins the workflow.
8 Comments
Claude is still the one I trust most for long-form drafts. It tends to keep the tone steadier across a full article instead of sounding like three different writers stitched together.
Same. ChatGPT is better when I need speed plus formatting help, but Claude usually needs less cleanup when the goal is actual readable prose.
Gemini surprised me here. For headline ideation and punchier intros, it can be more adventurous than both Claude and ChatGPT.
The biggest difference for me is how each one handles revision notes. Claude follows nuanced editorial feedback best, while ChatGPT is better at turning vague instructions into something usable fast.
I would have liked a little more on factual drift during longer drafts. ChatGPT sometimes starts strongest for me, then wanders by the fourth or fifth section.
For marketing copy I still lean ChatGPT. It is not always the most elegant, but it is very good at giving me multiple angles quickly enough to keep momentum.
This matched my experience almost exactly: Claude for essays, ChatGPT for collaborative drafting, Gemini for occasional spark when the other two feel too predictable.
What matters most is that the article treats writing quality as separate from raw capability. The smartest model is not automatically the best writing partner.
Sign in or create an account to leave a comment.